Robot Learning Manipulation Action Plans by “Watching†Unconstrained Videos from the World Wide Web
From Yezhou Yang, Yi Li, Cornelia Fermuller and Yiannis Aloimonos:
In order to advance action generation and creation in robots beyond simple learned schemas we need computational tools that allow us to automatically interpret and represent human actions. This paper presents a system that learns manipulation action plans by processing unconstrained videos from the World Wide Web. Its goal is to robustly generate the sequence of atomic actions of seen longer actions in video in order to acquire knowledge for robots. The lower level of the system consists of two convolutional neural network (CNN) based recognition modules, one for classifying the hand grasp type and the other for object recognition. The higher level is a probabilistic manipulation action grammar based parsing module that aims at generating visual sentences for robot manipulation.
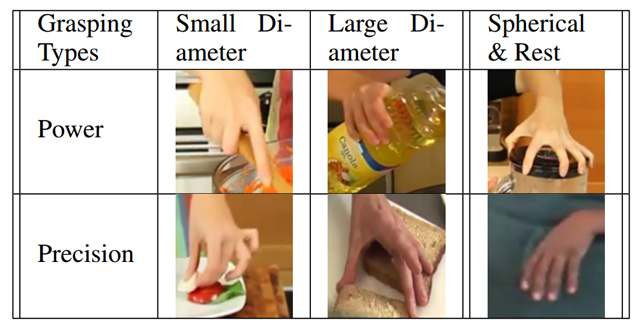
The list of the grasping types.
Experiments conducted on a publicly available unconstrained video dataset show that the system is able to learn manipulation actions by “watching” unconstrained videos with high accuracy.... (article at Kurzweilai.net) (original paper)
Featured Product

